Documentation From User Experience
- Marvin Lorber
- Documentation , Software , RDM
- April 11, 2025

Marvin Lorber
I received a bachelor’s degree in Scientific Programming and a master’s degree in „Energy Economics & Computer Science“ from the University of Applied Sciences Aachen. Prior to joining DKZ.2R as a consultant, I worked as a software engineer and developer in the industry for six years. As a consultant, I contribute skills in programming with Java, Python and C++, as well as experience with large, distributed software systems.
This post is a condensed version of a talk at our Data Compentcy College
If you regularly use scientific software written by others, or tried to replicate interesting research that relies on software, you have probably also invested weeks of work to solve a software problem or even given up on a software because of missing documentation. Finding a project that might be the solution to your problem and then failing to run the code is frustrating. Being unable to run a project you have built yourself years ago is even worse. Having experienced all those setbacks myself in the past I want to use this post to channel that frustration to fuel solutions for better documentation for our current and future projects.
Why Document?
Writing documentation takes time, a resource no researcher ever has enough of.
Also, writing documentation can be a thankless task.
Open Source developers who contribute to software documentation often report that they get less recognition compared to a code contribution. ¹
Given these facts the question is: Is writing documentation worth it?
The consensus among the open source community seems to be yes: there is no big project without great documentation, some even get funding just to improve the docs and there is a plethora of articles like this to encourage and inform better documentation.
For scientific software this is even more true. Whether you write a piece of software for your own research or a library to solve a common problem:
If other researchers can’t work out how to use it, the time you invested will be devalued.
Your research will have less impact, since others can’t replicate or build on your findings and libraries will go unused.
A few hours of your time can save future users weeks of work and ensure that your work gets proper recognition.
Also keep in mind that you might be a future user of your own software.
Where to document?
Before we dive into the information that needs to be recorded I’d first like to talk about where to record it. Because some of the projects we failed to utilize might have had some documentation somewhere, but in a separate file we could never find or access. To avoid that, our documentation should always be as close to the code as possible. In a README file in a common format like markdown or txt in the same folder/repository as the code, example files in the same location and comments right in the code. Even if a project grows larger and builds, for example, a separate website for the docs it should be linked, and the most important parts replicated in the README. This ensures that potential users always have access to the documentation. It is also easier to keep the software and documentation in sync when changes are made when they are in the same place. Separate documents tend to diverge. If your software is in a version control system like git, this also ensures that even the documentation for older versions of the software remains available.
What is this?
The first questions that we usually have when encountering a new software are:
- What functionality does this software provide?
- How is it different from other software with same functionality?
Whether we find a reference in a publication or stumble over it while researching solutions, these are the questions that need to be answered first. Consequently, answers to these question should be the first information a visitor finds in your project. Starting with a meaningful name they should be on the top of your README file, as gitlab and github both helpfully include those on the landing page of your project. This paragraph can also be the first thing we write for a new project. The general scope of our project and the reason why we can’t reuse existing software for our current research are usually known from the start, so we can write them down before we even write code.
How to install?
Once we know what a project is about and we want to use it, the next step from a users perspective is to get the software installed. After all, install requirements might still be a roadblock and before tackling a specific problem one needs an general idea how a software is operated. When reusing your own software, your system might still fulfill a lot of requirements from the development process. The easiest way to create a thorough step by step guide for your own project to help others using it is to install it on a fresh system (e.g. a virtual machine) and note down all steps that were required. If possible, it is also beneficial to have someone who was not involved in creating the software validate the install guide. Since the requirements might evolve during the development process this part is best created once you have a first usable version and then validated for every new version.
How to run?
The next step in our journey as users is usually to get an example application running, both to verify the installation has worked and to understand the way towards results. Examples are an extremely useful type of documentation and they are very easy to create. We probably ran every major use case of the software ourselves, for testing or results. By collecting the code snippets or command line prompts from the occasions and including them in the README or a separate examples file we can therefore create useful documentation with little extra time invested. Files for automated tests can also serve as a great source for examples.
How to use?
If we only want to reproduce and validate a research result our journey might end after the previous step. But most of the time it does not stop there. Usually users want to solve their own, and/or completely new problems using existing software. For this purpose a complete API reference is crucial, as we cannot predict the questions future users will have for our software. The API reference is a complete listing of all function names, their behavior, parameters and return values as well as objects that might be associated with them. Most programming languages support to include this information as comments within the code while some allow expressing type information with code itself. Where possible, those options should be used as they are usually well integrated into development environments and there are tools to extract the information into useful HTML or PDF documents with references. Having the API reference within the code also has advantages for speed and accuracy because we can write the documentation while writing code with the required information still fresh in our minds. Additionally, the documentation is close by if changes are needed. If you offer a command line interface (CLI) an incomplete command or the –help command it should print out the relevant documentation. Some languages even have frameworks that can populate the help text from the documentation comments.
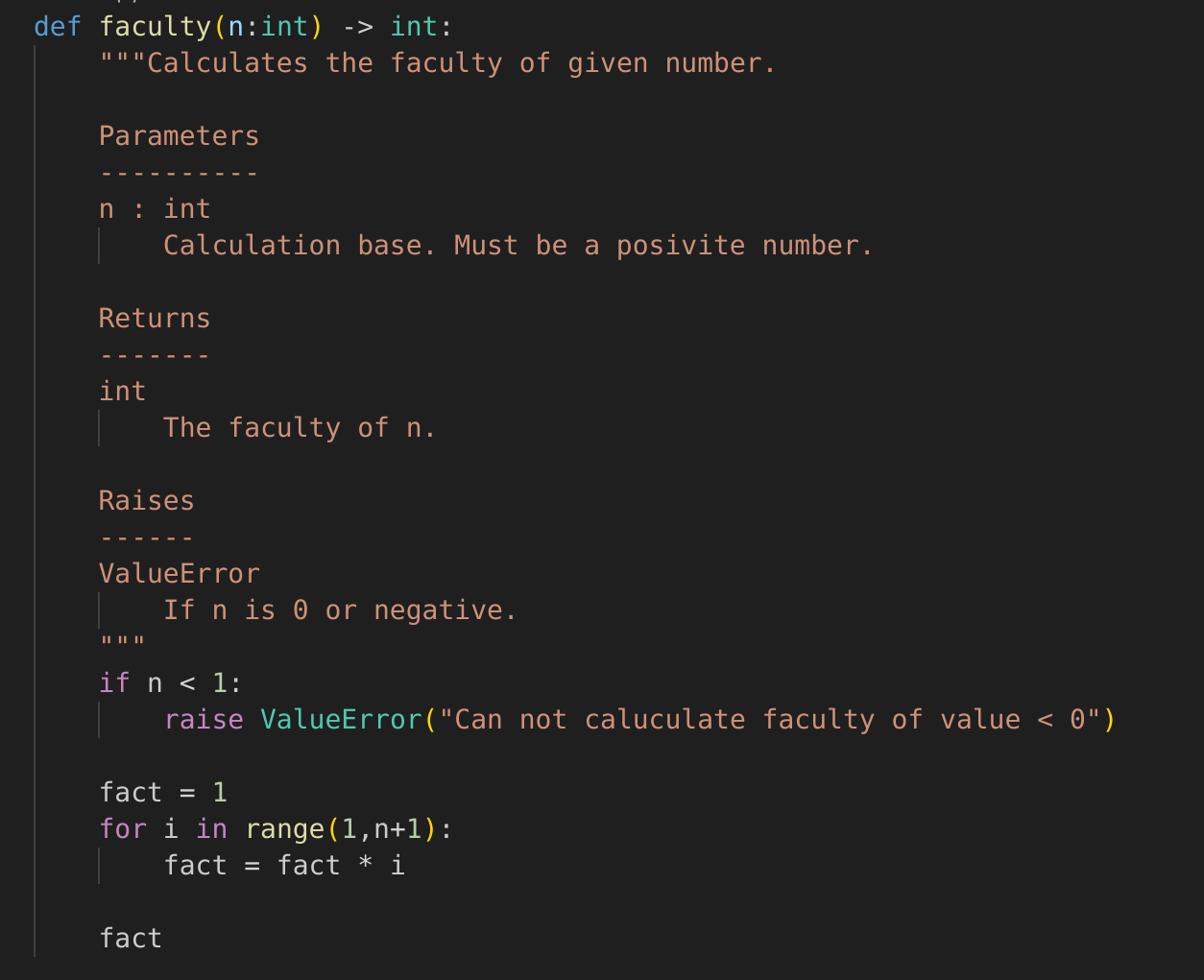 Example of inline documentation in python
Example of inline documentation in python
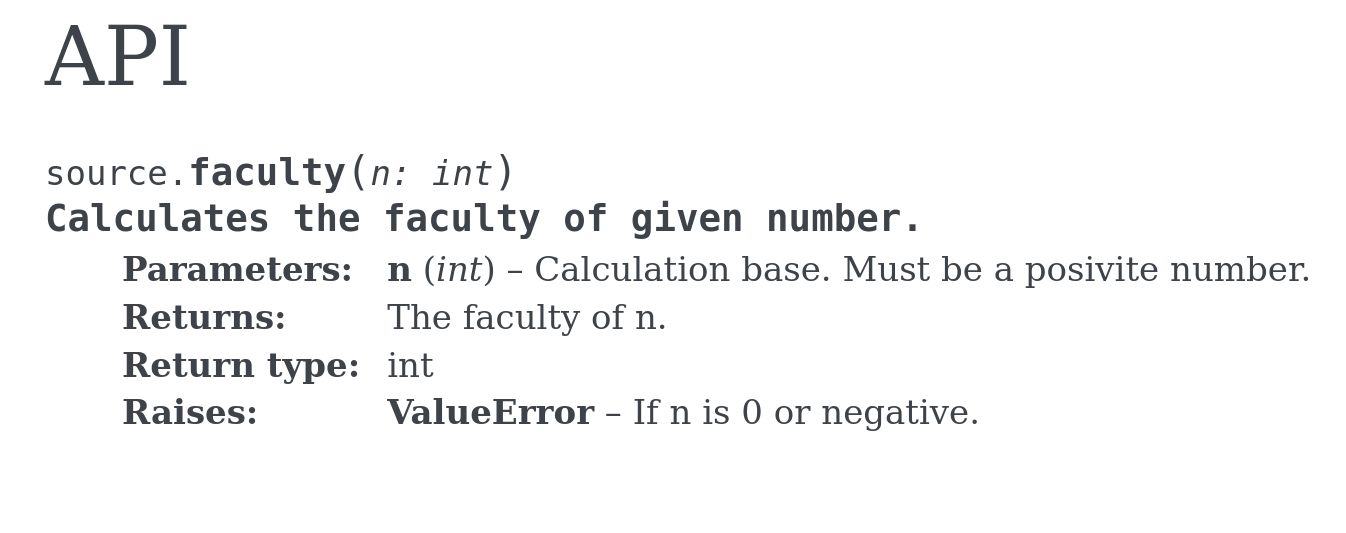 API reference doc generated from the inline comments
API reference doc generated from the inline comments
How to fix?
When we work with software it is inevitable that at some point something goes wrong. A good, meaningful error message can make the difference between a fix that takes a single click or one that takes hours of tracking the problem. While one may think of error handling as part of code, it is also part of documentation, and it is one that can help the developers themselves greatly. Collecting information, identifying the source of an error and pointing to common solutions can be crucial while hunting bugs as well as using the software.
How to contribute?
Besides the documentation for users there is also documentation for contributors.
For a small personal project that might only be yourself, but the time invested to record how to build the software and the reasoning behind design decisions might still pay off if you come back to the project after some time.
If you work in a team or on a public project having documentation for contributors can significantly speed up the collaboration.
Documentation for contributors can consist of:
- A guide to set up the development environment and how to build the software
- Code comments that explain why certain things are done
- A guide on how to propose or integrate new code (Patches, Merge/Pull Requests, etc.)
- A license, so contributors and users know the legal conditions of a project
Final Thoughts
Research software needs good documentation to be reusable by the developers themselves and others and support the reproducibility of study results, as well as the opportunity to answer new research questions more efficiently. When documenting your own software, It is easier to create the documentation during the development process than afterwards. Starting from a completely undocumented software, it can seem like an insurmountable task to create a good documentation, but incremental improvement of documentation is also worthwhile. Writing down the purpose of a software takes only a few minutes, as does integrating something you just run as an example. Correct but incomplete documentation is better than no documentation at all.
Documentation is an essential part of good software. Take pride and compliment others for contributions towards better documentation as you would for any other contribution.

